お初にお目にかかります稲本です。どうかコンゴトモヨロシク……
さて。
本稿ではSkyOnDemand 4.0で追加された新機能『マルチストリームコンバータ』をご紹介します。
マージやソート処理をより簡便に、そして高速にする最重要機密事項強力な機能ということで、その実力のほどを見ていきます。
『マルチストリームコンバータ』とは何者か
機能を適切に使うためには、まず何ができるのかを知らなければなりません。
そこで、Studioヘルプから該当項を引用してみます。
【『マルチストリームコンバータ』の特徴】
結合処理・集計処理・ソート処理は、Mapperとは別に、専用のコンポーネントが用意されています。
テーブルモデル型に特化したこれらのコンポーネントは、Multi-Stream Converter(マルチストリームコンバータ)という変換処理に特化した高速エンジン上で動作し、大容量データを扱うことに長けています。特にマルチコアCPU上では、リソースを有効に活用して並列で処理し、(従来のMapperと比較して)高速かつ省メモリで動作します。
Multi-Stream Converterの特性は、並列処理をサポートするコンポーネントとの組み合わせにおいて、最大の効果を発揮します。
また、処理ごとに専用のUIが用意され、直感的に操作・設定が可能になっています。
内容を要約すると、次の特徴が挙げられます。
- 追加されたコンポーネント「結合」「集計」「ソート」
- 処理が速い
- メモリの使用を抑えられる
- 大容量のデータを処理できる
- テーブルモデル型のみ処理できる
- 直感的に使用できる(専用のUIによって)
- 並列処理を行う(マルチコアCPUで効率が上がる)
要約の感触としては、スクリプトの処理速度を向上させる手段として使わない手はないと言えます。
【既存のコンポーネントを選択するケース】
良いことずくめな『マルチストリームコンバータ』ですが、やはり不得手もあります。そのような状況では既存のコンポーネントの出番となります。
同じくStudioヘルプの内容ですが、本稿の主題ではないためこちらは概略とします。
※引用元がテーブル形式なので、原文を持ってこられませんでした。無念
- XML型データモデルのマッピング
- 「Mapperロジック」の複合
- 3点以上のデータ結合(「結合」コンポーネント)
- 大文字/小文字の優先順位指定(「ソート」コンポーネント)
これらの制限は検証にも影響するため留意しておきます。
『マルチストリームコンバータ』の実力を計る
では、要約した特徴を基に、『マルチストリームコンバータ』の実力を試します。
本稿では、スクリプトの処理速度向上の確認を主な目的として、次の通り検証します。
評価
『マルチストリームコンバータ』によってこれまでよりパフォーマンスが向上することを確認したいので、既存コンポーネントと追加コンポーネントの処理時間を比較します。
また、『マルチストリームコンバータ』は並列処理によって効率的に動作するようですので、せっかくですからCPUコア数を増やして効果を確認しておきたいところ。
SkyOnDemandではスケールアップオプションの適用によってCPUコア数が増えますので、連携サーバの各スケールについても同様に比較します。
- 評価項目○処理時間…スクリプトの実行時間
- 評価基準①既存コンポーネントとの比較
- 評価基準②連携サーバスケール別の比較
試行
評価方法が決まりましたので、評価対象となるデータの取得方法を決めます。
今回の検証ではコンポーネントの実行結果を取得できればよいので、追加コンポーネントから各処理1点ずつ、それに既存コンポーネントも合わせて用意した検証スクリプトを試行します。
また、連携サーバのスケールごとに評価したいので、使用できるすべてのスケールで試行します。
- 試行単位①追加コンポーネント…「結合」「集計」「ソート」
- 試行単位②既存コンポーネント…「Mapper」「Merge」※処理を追加コンポーネントに合わせる
- 試行単位③連携サーバスケール…〔Small-1vCPU〕〔Medium-2vCPU〕〔Large-4vCPU〕
- 結果取得方法○処理時間…マイログよりスクリプトの実行時間を取得する
※スケールの仕様は本稿執筆時点のものです。今後変更される可能性があります
準備
検証スクリプトと入力データを準備します。
検証スクリプトは、追加コンポーネントを含んだスクリプト3点と、追加コンポーネントと同等の処理を行う既存コンポーネントのロジックを含んだスクリプト3点、計6点を用意します。
入力データは、特徴の一つである大容量データ処理を行わせたいので、ある程度の大容量データ(10万件程度)を2点用意します。
- 検証スクリプト①追加コンポーネント3点…「結合」「集計」「ソート」
- 検証スクリプト②既存ロジック3点…「And-Integrate」「グループ化」「キーによるソート」
- 入力データ2点…同一フォーマットかつ内容別の大容量データ
検証準備
早速、検証の準備に入りましょう。
まずは検証用の入力データがないと検証スクリプトを組むことができません。検証に都合の良い条件として大容量で準備しやすいデータがあるとよいのですが、はてそんなデータどこに…なんて、あります、都合の良いデータ。
本稿では入力データとして日本郵便株式会社が公開している郵便番号データを使います。全国の郵便番号が含まれていてそのデータ件数は10万件超。しかもキーが重複したレコードもあり検証に最適です。さらになんとこのデータは著作権を気にする必要がありません。つまり、使用・再配布・移植・改変すべて自由。検証にあたり最も手間のかかるテストデータの準備があっという間に終わってしまいます。
郵便番号データダウンロード - 日本郵便

検証用の入力データとして2点用意しなければならないので、このデータを適当に分割して使用します。
ダウンロードした郵便番号データは列名を含まないので、『郵便番号データの説明』の『郵便番号データファイルの形式等』を参考に列名を決めました。
全国地方公共団体コード,旧郵便番号,郵便番号,都道府県名(カナ),市区町村名(カナ),町域名(カナ),都道府県名,市区町村名,町域名,町域が郵便番号二以上,小字毎の番地起番町域,丁目の有る町域,郵便番号が町域二以上,更新,変更理由
次に検証スクリプトを用意します。「結合」「集計」「ソート」コンポーネントが使われているもの3点、「Mapper」「Merge」コンポーネントの「And-Integrate」「グループ化」「キーによるソート」ロジックが使われているもの3点のスクリプトを用意しました。
01)「結合」コンポーネント検証スクリプト

01)「結合」コンポーネント - スクリプト全景
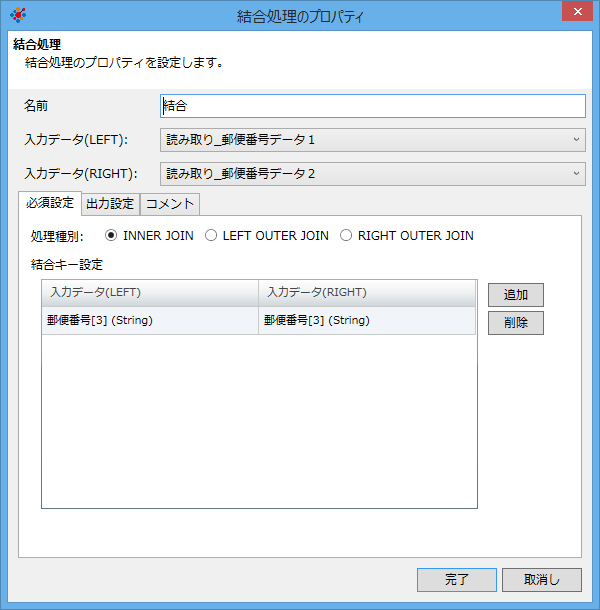
01)「結合」コンポーネント - 「結合」プロパティ
02)「集計」コンポーネント検証スクリプト
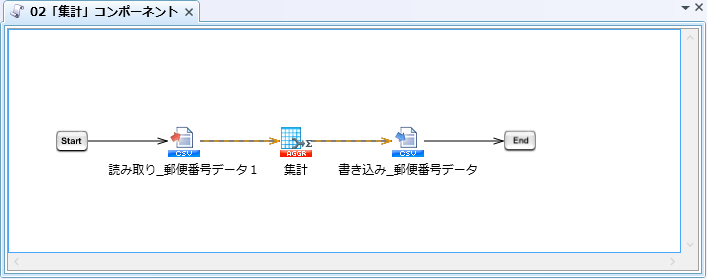
02)「集計」コンポーネント - スクリプト全景

02)「集計」コンポーネント - 「集計」プロパティ
03)「ソート」コンポーネント検証スクリプト
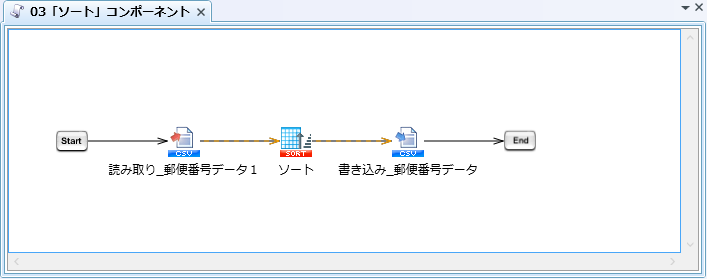
03)「ソート」コンポーネント - スクリプト全景

03)「ソート」コンポーネント - 「ソート」プロパティ
追加コンポーネントは、それぞれ独立したコンポーネントであるためマッピング不要です。
配線を考えることなく手軽に配置できます。
04)「And-Integrate」ロジック検証スクリプト

04)「And-Integrate」ロジック - スクリプト全景

04)「And-Integrate」ロジック - 「Merge」プロパティ
05)「グループ化」ロジック検証スクリプト

05)「グループ化」ロジック - スクリプト全景

05)「グループ化」ロジック - 「Mapper」[グループ化]プロパティ

05)「グループ化」ロジック - 「Mapper」[テーブル化]プロパティ
06)「キーによるソート」ロジック検証スクリプト

06)「キーによるソート」ロジック - スクリプト全景

06)「キーによるソート」ロジック - 「Mapper」プロパティ
00)『マルチストリームコンバータ』使用時の留意事項
『マルチストリームコンバータ』にいかんなく性能を発揮してもらうために、Studioヘルプを参考に次の点に留意してスクリプトを組みました。
- 一連のプロセスを『並列処理をサポートするコンポーネント』で統一する
- 「CSVファイル読み取り」コンポーネントで[並列処理設定を有効にする]
追加コンポーネントは並列処理の適用により処理速度が向上します。一連のプロセスに並列処理を適用するためには、追加コンポーネントの入力元と出力先双方が並列処理に対応していなければなりません。
そこで検証スクリプトでは、並列処理をサポートしているCSVアダプタを使用しています。
さらに、「CSVファイル読み取り」コンポーネントは既定の動作では並列処理が適用されません。並列処理を適用するために、[並列処理設定]タブより[並列処理設定を有効にする]にチェックを入れました。
![「CSVファイル読み取り」コンポーネント[並列処理設定]タブ](https://cdn.clipkit.co/tenants/243/item_images/images/000/000/925/original/45a5c262-7353-4597-8e12-8cb57fa3d1e7.png?1497256771)
「CSVファイル読み取り」コンポーネント[並列処理設定]タブ
なお、検証スクリプトでは考慮する必要がありませんでしたが、実戦用にスクリプトを組む際には次の点にも留意しなければなりません。
- 「結合」「集計」コンポーネントの出力データは並び順が保証されない
並列処理が適用されることで、追加コンポーネントが出力するデータは並び順がバラバラになります。
出力データの並び順を指定したいのであれば、「結合」「集計」コンポーネントの後に「ソート」コンポーネントを配置して改めてデータを並び替えなければなりません。
検証試行
準備が整ったところで、検証スクリプトを実行していきます。
これまでに準備した検証スクリプト6点と入力データ2点を連携サーバにアップロードします。
後でスケール別に結果を比較しますので、各スケール計3基の連携サーバにアップロードします。
【検証スクリプト6点】
- 01「結合」コンポーネント
- 02「集計」コンポーネント
- 03「ソート」コンポーネント
- 04「And-Integrate」ロジック
- 05「グループ化」ロジック
- 06「キーによるソート」ロジック

検証環境 - デザイナ
【入力データ2点】
- KEN_ALL_1.CSV(10万件)
- KEN_ALL_2.CSV(10万件)
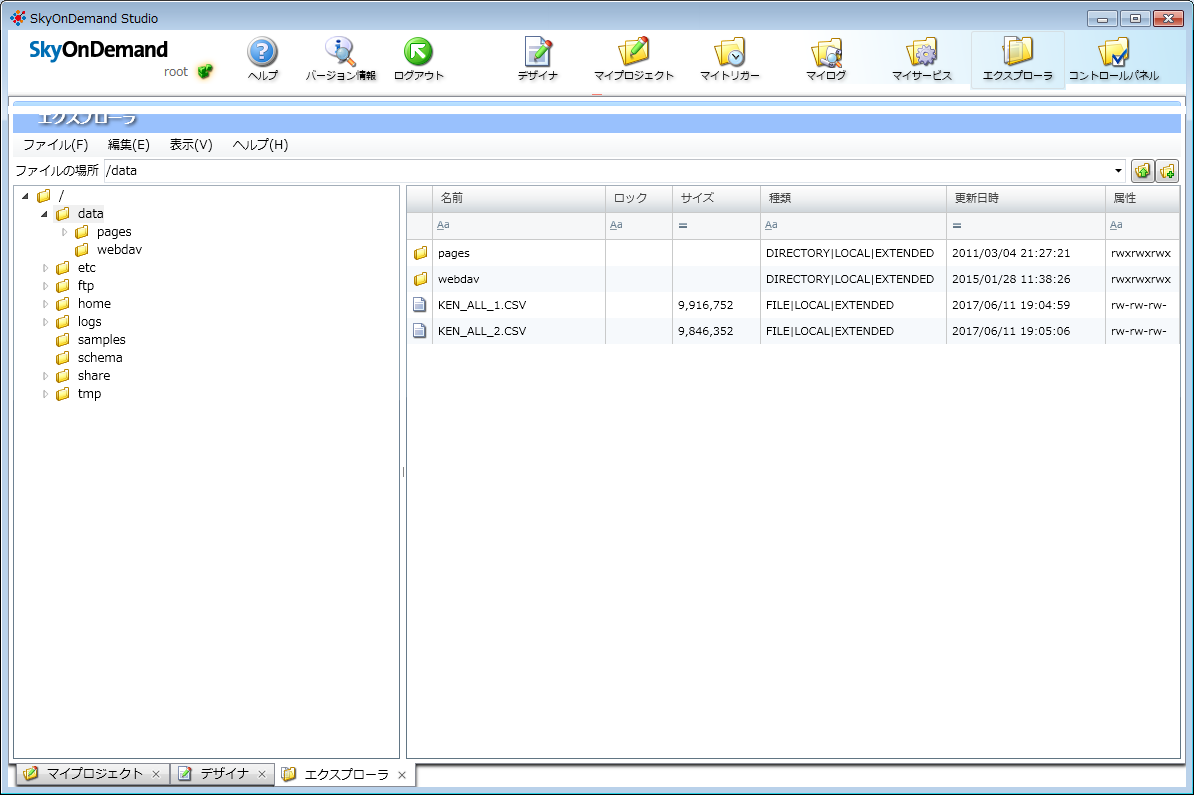
検証環境 - エクスプローラ
ここからは地味にスクリプトを試行していきます。
検証スクリプト6点×スケール3種の合計18パターン。
結果として概算が取れれば充分ですので、試行回数は各1回とします。
試行結果
という訳で、試行結果は次の通りです。(地味な試行過程は省略省略!)
【結果全体】
| スクリプト\スケール | Small(1vCPU) | Medium(2vCPU) | Large(4vCPU) |
|---|---|---|---|
| 「結合」コンポーネント | 10,667 | 5,298 | 3,200 |
| 「集計」コンポーネント | 2,946 | 1,184 | 596 |
| 「ソート」コンポーネント | 5,840 | 1,989 | 1,356 |
| 「And-Integrate」ロジック | 42,507 | 17,267 | 12,974 |
| 「グループ化」ロジック | 499,568 | 196,632 | 221,156 |
| 「キーによるソート」ロジック | 4,181 | 1,247 | 1,370 |
| 処理時間 単位:ミリ秒 | |||
評価
一通りデータが揃いましたので、ここからは評価観点を基に個別に評価していきます。
【比較「結合」「And-Integrate」】
| スクリプト\スケール | Small(1vCPU) | Medium(2vCPU) | Large(4vCPU) |
|---|---|---|---|
| 「結合」コンポーネント | (100%)10,667 | (201%)5,298 | (333%)3,200 |
| 「And-Integrate」ロジック | 42,507 | 17,267 | 12,974 |
| 処理時間 単位:ミリ秒 | |||
結果は良好です。既存コンポーネントと比べておよそ4倍の速度が出ています。10万件のデータ2点のマージ結果としてかなり良い線行っているのではないでしょうか。
スケールアップによる効果は、SmallからMediumについては速度比201%とvCPUの数の差がそのまま結果に出ているようですが、SmallからLargeについては速度比333%と少々物足りない結果になっています。この辺りはスケールの差が顕著に出ないだけなのか、それともどこかボトルネックになっている要素があるのか、少し疑問の残る結果となりました。
【比較「集計」「グループ化」】
| スクリプト\スケール | Small(1vCPU) | Medium(2vCPU) | Large(4vCPU) |
|---|---|---|---|
| 「集計」コンポーネント | (100%)2,946 | (249%)1,184 | (494%)596 |
| 「グループ化」ロジック | 499,568 | 196,632 | 221,156 |
| 処理時間 単位:ミリ秒 | |||
かなり顕著に性能差が出ました。Smallで170倍の速度です。ここまで差が出ると同等のロジックを再現できているか少々不安になりますが、出力データは一致していましたので実力です。
スケールアップの効果も、SmallからMediumで速度比249%、SmallからLargeで速度比484%と、vCPUの数が綺麗に結果へ反映されています。
【比較「ソート」「キーによるソート」】
| スクリプト\スケール | Small(1vCPU) | Medium(2vCPU) | Large(4vCPU) |
|---|---|---|---|
| 「ソート」コンポーネント | (100%)5,840 | (293%)1,989 | (431%)1,356 |
| 「キーによるソート」ロジック | 4,181 | 1,247 | 1,370 |
| 処理時間 単位:ミリ秒 | |||
おっと、思いのほか差が出ませんでした。むしろ既存コンポーネントが優秀と言うべきでしょうか。
多少想定外の結果となってしまいましたが、この現象は仕様によってある程度説明がつきそうです。
ここまで触れてきませんでしたが、実は「ソート」コンポーネントは部分的に並列処理が適用されません。出力結果として指定の並び順を担保しなければならず、必然的に直列処理となるためです。
これはStudioヘルプでも確認できる仕様で、『並列処理をサポートするコンポーネント』を読むと分かるようになっています。
受け渡された入力データを複数のスレッドで並列に処理し、ソートを行います。(データのサイズやCPUのコア数によっては、中間データを一時ファイルに出力する場合があります。)
順序を保証するため分割は行わず、ソートした結果を出力します。
「結合」「集計」コンポーネントに比べ結果が振るわない一因と考えられます。
このように、処理速度面では既存コンポーネントと変わりのない「ソート」コンポーネントですが、何気なく3つ以上のキーによるソートが可能(既存コンポーネントでは不可)となっており、利便性が向上しています。
とは言え、既存コンポーネントに負けてはいられません。今後さらなる性能向上を目指す所存。
なお、スケールアップの効果については、SmallからMediumで速度比293%、SmallからLargeで速度比431%と、こちらは順当にvCPUの数が結果に反映されています。
検証結果
さて、本稿では、先に挙げたものの中から次の特徴を検証しました。
- 追加されたコンポーネント「結合」「集計」「ソート」
- 処理が速い
- 大容量のデータを処理できる
- テーブルモデル型のみ処理できる
- 並列処理を行う(マルチコアCPUで効率が上がる)
試行結果と評価より、「追加のコンポーネント」は「(既存コンポーネントと比べて)処理が速く」「大容量のデータを処理でき」「並列処理が行われている」ことが確認できました。(追加コンポーネントの検証スクリプトは、さりげなく「テーブルモデル型」のみで組んでいます)
「結合」「集計」「ソート」、これまでパフォーマンスの問題などによりテンポラリDBを利用する機会も多かったこれらのデータ操作ですが、『マルチストリームコンバータ』によってテンポラリDBを経由しなくてもよくなるかもしれません。
テンポラリDBを利用した処理との比較もいずれ試してみたいと考えています。
本稿をお役立ていただけましたら幸いです。ではまた。
免責など
●検証除外項目
お気づきの方もいらっしゃるかと思いますが、本稿では次の特徴について、検証観点の違いや確認の難度などを理由に検証から除外しています。
- 直感的に使用できる(専用のUIによって)
- メモリの使用を抑えられる
●スケールアップオプション
本稿では並列処理の効果を確認するためvCPUの増加に焦点を当てましたが、スケールアップによりvCPUの増加に加えてメモリ容量も増加します。データ量などの要因によりメモリ使用量が増減することで処理時間が変動することがあります。

