2018.05.01
DataSpider Cloudの正規表現置換ロジックで文字列を加工するのです
花粉症のシーズンも終盤に入り、無限鼻水生成装置の任をようやく解いてもらえそうな稲本です。
早速ながら。
本稿では、DataSpider Cloudでのスクリプト開発に便利な正規表現置換ロジックを紹介します。
文字列の加工に威力を発揮しますので、この機会にお試しいただけると幸いです。
早速ながら。
本稿では、DataSpider Cloudでのスクリプト開発に便利な正規表現置換ロジックを紹介します。
文字列の加工に威力を発揮しますので、この機会にお試しいただけると幸いです。
「正規表現置換」ロジック
正規表現置換ロジックは、入力された文字列の正規表現に一致する部分を指定の文字列に置き換えるロジックです。
置き換えの条件に正規表現を利用できるため、単純な文字列の置換と比べ柔軟な処理ができます。
置き換えの条件に正規表現を利用できるため、単純な文字列の置換と比べ柔軟な処理ができます。
Studioヘルプ - 「正規表現置換」ロジック

[ドキュメントMapper]正規表現置換
リンク先はドキュメントMapperですが、その他にも各種Mapperで使用できます。
【Mapper一覧】
- ドキュメントMapper
- 変数Mapper
- マージMapper
使い方

01.正規表現置換ロジック使用例① - Mapper配置例
シンプルに正規表現置換ロジックと単純な繰り返しロジックのみ配置しました。

02.正規表現置換ロジック使用例② - ロジックプロパティ
ロジックの設定項目は2点。置換条件となる正規表現を入力する[置換前文字列]と、置き換える文字列を入力する[置換後文字列]です。
ロジックアイコンの場所

03.ツールパレット - 正規表現置換ロジック
ロジックアイコンは、ツールパレットの文字列カテゴリにあります。
サンプルスクリプト
本稿では、次の構成のスクリプトを使って動作を確認しました。

04.サンプルスクリプト
次項からの使用例では、「①CSV読み込み - 入力」の入力データおよび「③正規表現置換 - ○○」内に配置した正規表現置換ロジックのプロパティを変更しています。
使用例① 改行の除去
ではまず改行の除去から参ります。
正規表現には改行を表す構文が揃っていますし、あわせて論理演算もできますので、初めの一歩として良い感じです。
ということで、入力データから改行を除去してみましょう。
正規表現には改行を表す構文が揃っていますし、あわせて論理演算もできますので、初めの一歩として良い感じです。
ということで、入力データから改行を除去してみましょう。
入力データ
"[CR] [LF] [CRLF] "
入力データ.csv
記事にすると文字コードが自動的に調整されてしまってよく分からなくなっていますが、WindowsやLinux、あるいはmacOSと呼ばれるOSで使われている改行には、3つのパターンがあります。
それが、CR(キャリッジリターン)、LF(ラインフィード)、CR+LFです。
実際の入力データでは、それら3種の改行を[]内の項目右端に記述しています。
※全体を""で閉じているのは、CSVアダプタに1項のデータとして扱ってもらうためです
それが、CR(キャリッジリターン)、LF(ラインフィード)、CR+LFです。
実際の入力データでは、それら3種の改行を[]内の項目右端に記述しています。
※全体を""で閉じているのは、CSVアダプタに1項のデータとして扱ってもらうためです
ロジックプロパティ
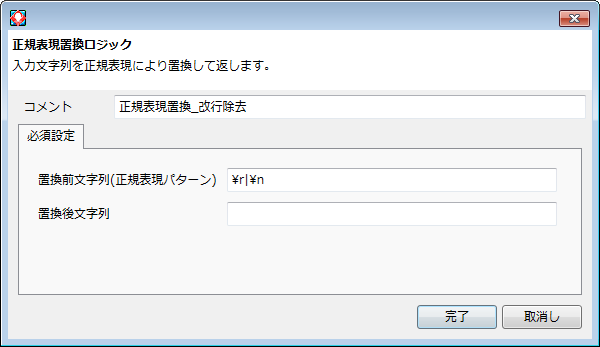
05.正規表現置換ロジック - 改行除去
正規表現には多様な記述方法がありますので一例となりますが
- CRを表す構文「¥r」
- LFを表す構文「¥n」
- OR論理演算を行う「|」
を組み合わせています。
これにより、CRかLFに該当する箇所が正規表現に一致しますので、他の文字へ置き換えられます。
ここでは、置換後文字列に何も入力しないことで除去として動作するようにしています。
これにより、CRかLFに該当する箇所が正規表現に一致しますので、他の文字へ置き換えられます。
ここでは、置換後文字列に何も入力しないことで除去として動作するようにしています。
処理結果
"[CR][LF][CRLF]"
処理結果データ.csv
このように改行が除去された状態を得られます。
使用例② N個の半角スペースを1個にする
次は、N個(1個以上)の半角スペースを1個に減らします。
これも特に難しいことはなく、正規表現の構文でさくっと実現できます。
これも特に難しいことはなく、正規表現の構文でさくっと実現できます。
入力データ
"[空白1つ] [空白2つ] [空白3つ] [空白4つ] [空白5つ] "
入力データ.csv
[]内の項目通り、1個から5個の半角スペースを記述しています。
ロジックプロパティ

06.正規表現置換ロジック - 空白N個を1個に
- 半角スペースを表す「¥s」
- 1回以上の出現を表す「X+」
を組み合わせています。
これにより半角スペースが1個以上あると正規表現に一致しますので、文字を置き換えられます。
画像では分かりませんが、置換後文字列に半角スペースを1個入力しています。
これにより半角スペースが1個以上あると正規表現に一致しますので、文字を置き換えられます。
画像では分かりませんが、置換後文字列に半角スペースを1個入力しています。
処理結果
"[空白1つ] [空白2つ] [空白3つ] [空白4つ] [空白5つ] "
処理結果データ.csv
項目間の半角スペースが1個になりました。
使用例③ 通貨表記の変更(¥を円に)
最後に、日本円の通貨表記を¥5,000から5,000円に変えてみましょう。
少々複雑な正規表現になりますので、正規表現化のプロセスもご紹介します。
入力データ
"¥10,000" "¥2,500,000" "¥4,200" "¥560"
入力データ.csv
半角¥を記事にするとバックスラッシュになってしまうため、全角¥を入力データとしました。
ロジックプロパティ
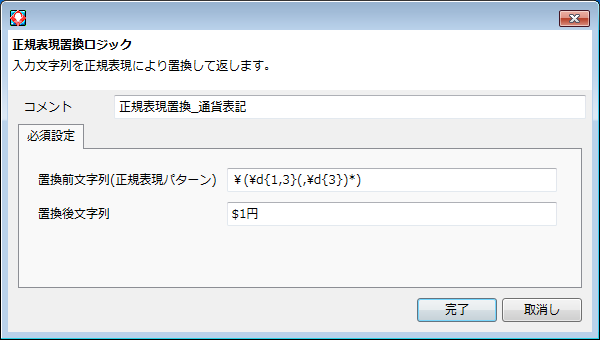
07.正規表現置換ロジック - 通貨表記変更
これまでの例より複雑な正規表現と、置換語文字列には初見の記述があります。
使用した構文は次の通り。
使用した構文は次の通り。
- グループ化を行う「()」
- 数字を表す「¥d」
- n回以上m回以下の出現を表す「X{n,m}」
- n回の出現を表す「X{n}」
- 0回以上の出現を表す「X*」
- グループ番号nを前方参照する「$n」
構文が増えて動作を想像するのが難しくなってきましたが、ひとまず処理結果を確認しましょう。
処理結果
"10,000円" "2,500,000円" "4,200円" "560円"
処理結果データ.csv
先頭の¥が除去され、最後に円が追加されました。
正規表現化
この例で使用した正規表現は、おおむね次のようなプロセスで構築しました。

08.正規表現化プロセス
このプロセスで重要な点が、⑥のグループ化です。
入力データに対して正規表現を一致させるだけであれば、この工程は不要です。
しかし、今回は処理結果に入力データの数値部分を反映する必要がありました。
それを実現するために使用した構文が「$n」です。
正規表現では、正規表現に一致した内容をグループごとに一時的に記録します。
「$n」は、この記録した内容を参照して取り出せる構文です。
⑥により入力データの数値部分をグループ化して、置換後文字列で取り出せるようにしています。
ここで$1としたのは、記録される内容の順序が次のようになるためです。
入力データに対して正規表現を一致させるだけであれば、この工程は不要です。
しかし、今回は処理結果に入力データの数値部分を反映する必要がありました。
それを実現するために使用した構文が「$n」です。
正規表現では、正規表現に一致した内容をグループごとに一時的に記録します。
「$n」は、この記録した内容を参照して取り出せる構文です。
⑥により入力データの数値部分をグループ化して、置換後文字列で取り出せるようにしています。
ここで$1としたのは、記録される内容の順序が次のようになるためです。
- $0…¥(\d{1,3}(,\d{3})*)
- $1…(\d{1,3}(,\d{3})*)
- $2…(,\d{3})*
※$0には正規表現全体に一致した内容が記録されます
終わり
駆け足になりましたが、正規表現置換ロジックのご紹介はひとまず以上となります。
正規表現を利用できる状況は案外多いのではないかと思います。
文字列の加工が必要となった際にはぜひご一考ください。
本稿をお役立ていただけましたら幸いです。ではまた。
正規表現を利用できる状況は案外多いのではないかと思います。
文字列の加工が必要となった際にはぜひご一考ください。
本稿をお役立ていただけましたら幸いです。ではまた。
補足 - 使用できる正規表現について
正規表現置換ロジックで使用できる正規表現は、java.util.regex.Patternに準じています。
(Studioヘルプにも記載されています。あわせてご参照ください)
構文をご確認いただく際には、次のリンク先などをご参照ください。
(Studioヘルプにも記載されています。あわせてご参照ください)
構文をご確認いただく際には、次のリンク先などをご参照ください。
Pattern (Java Platform SE 8)

Java(TM) Platform, Standard Edition 8 API Specification
※OracleとJavaは、Oracle Corporation 及びその子会社、関連会社の米国及びその他の国における登録商標です。文中の社名、商品名等は各社の商標または登録商標である場合があります。



【機能】入力文字列を正規表現により置換して返します。