2020.10.26
ApexでGCPのVision APIを使ってみた

はじめに
こんにちは。テラスカイの山口です。
今回はGoogle Cloud Platform(以下GCP)のVision APIをApexからコールし、PDFファイルの文字解析を行ってみましたので解説します。
今回はGoogle Cloud Platform(以下GCP)のVision APIをApexからコールし、PDFファイルの文字解析を行ってみましたので解説します。
Vision APIとは
Google Cloud Platformで提供されている画像解析のためのAPIです。画像の他、ドキュメント(PDF / TIFF)の読み取りにも対応しています。
料金
現在、最初の 1,000 ユニット/月まで無料で利用することができます。
1,001ユニット以降は利用する機能ごとに料金が異なりますので、Google Cloudの公式ページでご確認ください。
1,001ユニット以降は利用する機能ごとに料金が異なりますので、Google Cloudの公式ページでご確認ください。

Google Cloud Platformの設定
Vision APIの有効化
まず、Vision APIを利用するために、APIを有効化します。
Google Cloud Platformのナビゲーションメニューから"APIとサービス">"APIとサービスの有効化"のリンクをクリックします。
Google Cloud Platformのナビゲーションメニューから"APIとサービス">"APIとサービスの有効化"のリンクをクリックします。

次に、"vision"と検索し、"Cloud Vision API"を選択し、有効化します。


認証情報の設定
"APIとサービス"の"認証情報"をクリックし、ページ上部の"認証情報を作成"を押下後、"OAuthクライアントID"を選択します。

アプリケーションの種類で"ウェブアプリケーション"を選択します。名前は任意の名前を入力して下さい。入力後、作成ボタンを押下します。

Salesforceの認証設定
認証プロバイダの設定
Salesforce環境の認証プロバイダの設定をします。設定から"認証"と検索し、"認証プロバイダ"を選択し、新規をクリックします。
プロバイダタイプで"Open ID Connect"を選び、以下の必要情報を入力します。
プロバイダタイプで"Open ID Connect"を選び、以下の必要情報を入力します。

| 属性 | 値 |
|---|---|
| 名前 | 任意 |
| URL接頭辞 | 任意 |
| コンシューマ鍵 | 先に登録したGCPのOAuth 2.0 クライアント IDで参照できるクライアントID |
| コンシューマの秘密 | 先に登録したGCPのOAuth 2.0 クライアント IDで参照できるクライアントシークレット |
| 承認エンドポイントURL | https://accounts.google.com/o/oauth2/auth?access_type=offline&approval_prompt=force |
| トークンエンドポイント URL | https://oauth2.googleapis.com/token |
| デフォルトの範囲 | https://www.googleapis.com/auth/cloud-platform https://www.googleapis.com/auth/cloud-vision |
| ヘッダーでアクセストークンを送信 | チェック |
| API 応答にコンシューマの秘密を含める | チェック |
登録後、参照画面の下部に表示されるコールバックURLをGCPの認証情報の"承認済みのリダイレクトURI"に設定します。

指定ログイン情報の設定
次に、指定ログイン情報の設定を行います。指定ログイン情報はVIsion APIのエンドポイントと、Vision APIの解析結果のJSONファイルが格納されるGoogle Cloud Storageからファイルを取得するためのCloud Storageのエンドポイントの2つを登録します。
設定から"指定"と検索し、"指定ログイン情報"を選択、"新規指定ログイン情報"ボタンを押下します。
設定から"指定"と検索し、"指定ログイン情報"を選択、"新規指定ログイン情報"ボタンを押下します。

以下のように2つの指定ログイン情報を登録します。
【Vision APIエンドポイント】
| 属性 | 値 |
|---|---|
| 表示ラベル | 任意 |
| 名前 | 任意 |
| URL | https://vision.googleapis.com/v1/files:asyncBatchAnnotate |
| ID種別 | 指定ユーザ |
| 認証プロトコル | OAuth 2.0 |
| 認証プロバイダ | 先に作成した認証プロバイダ設定をルックアップで選択 |
| 範囲 | https://www.googleapis.com/auth/cloud-platform https://www.googleapis.com/auth/cloud-vision |
| 保存時に認証フローを開始 | チェック |
| 認証ヘッダーを生成 | チェック |
| HTTP ヘッダーの差し込み項目を許可 | チェック |
| HTTP 本文の差し込み項目を許可 | チェック |
※OAuthの範囲の区切り文字は半角スペースです
【Cloud Storageエンドポイント】
| 属性 | 値 |
|---|---|
| 表示ラベル | 任意 |
| 名前 | 任意 |
| URL | https://storage.googleapis.com |
| ID 種別 | 指定ユーザ |
| 認証プロトコル | OAuth 2.0 |
| 認証プロバイダ | 先に作成した認証プロバイダ設定をルックアップで選択 |
| 範囲 | https://www.googleapis.com/auth/cloud-platform |
| 保存時に認証フローを開始 | チェック |
| 認証ヘッダーを生成 | チェック |
| HTTP ヘッダーの差し込み項目を許可 | チェック |
| HTTP 本文の差し込み項目を許可 | チェック |
これで認証情報の設定は完了です。
Google Cloud Storageのバケット作成
Google Cloud Storageのバケットを作成します。
作成するバケットはOCR解析対象のファイルを格納するバケットと解析結果のJSONファイルを格納するバケットの2つを作成します。
Google Cloud Platformのナビゲーションメニューで"Storage"を選択し、バケット作成をクリックします。
作成するバケットはOCR解析対象のファイルを格納するバケットと解析結果のJSONファイルを格納するバケットの2つを作成します。
Google Cloud Platformのナビゲーションメニューで"Storage"を選択し、バケット作成をクリックします。

入力フォームに従って入力し、作成ボタンを押下します。設定内容は任意です。
バケットが作成できたら、解析対象のPDFファイルを格納します。今回はIntegration Architecture デザイナーの受験ガイドを格納しています。
バケットが作成できたら、解析対象のPDFファイルを格納します。今回はIntegration Architecture デザイナーの受験ガイドを格納しています。
Salesforce 認定 Integration Architecture デザイナー受験ガイド

アーキテクチャ環境を評価し、エンドツーエンドの統合要件を満たす、信頼性とスケーラビリティに優れたテクニカルソリューションを Salesforce Platform 上で設計する知識があることを証明します。
Apex実装
Vision APIコールアウト
コード実装例を以下に示します。
public with sharing class GCPLogic {
@Future(callout=true)
public static void callCloudVisionAPI(String inputFilePass,String outputFolderPass) {
Http http = new Http();
HttpRequest req = new HttpRequest();
//指定ログイン情報で設定した名前を設定する
String reqPath = 'callout:GCP_visionapi';
req.setEndpoint(reqPath);
req.setMethod('POST');
req.setHeader('content-type', 'application/json');
//GCPのプロジェクトIDを指定
req.setHeader('x-goog-project-id', '696775376003');
//JSONを生成
JSONGenerator requests = JSON.createGenerator(true);
requests.writeStartObject();
requests.writeFieldName('requests');
requests.writeStartArray();
requests.writeStartObject();
requests.writeFieldName('inputConfig');
requests.writeStartObject();
requests.writeFieldName('gcsSource');
requests.writeStartObject();
requests.writeStringField('uri', inputFilePass);
requests.writeEndObject();
requests.writeStringField('mimeType', 'application/pdf');
requests.writeEndObject();
requests.writeFieldName('features');
requests.writeStartArray();
requests.writeStartObject();
requests.writeStringField('type', 'DOCUMENT_TEXT_DETECTION');
requests.writeEndObject();
requests.writeEndArray();
requests.writeFieldName('outputConfig');
requests.writeStartObject();
requests.writeFieldName('gcsDestination');
requests.writeStartObject();
requests.writeStringField('uri', outputFolderPass);
requests.writeEndObject();
requests.writeNumberField('batchSize', 1);
requests.writeEndObject();
requests.writeEndObject();
requests.writeEndArray();
requests.writeEndObject();
String reqBody = requests.getAsString();
System.debug(reqBody);
req.setBody(reqBody);
HttpResponse res = http.send(req);
if (res.getStatusCode() == 200) {
Map<String, Object> results = (Map<String, Object>) JSON.deserializeUntyped(res.getBody());
System.debug('成功:'+results);
}else {
Map<String, Object> results = (Map<String, Object>) JSON.deserializeUntyped(res.getBody());
System.debug('エラー:'+results);
}
}
}GCPLogic.cls
リクエストBodyのjsonは以下のようになります。
{
"requests": [
{
"inputConfig": {
"gcsSource": {
"uri": "ストレージのファイルパス"
},
"mimeType": "application/pdf"
},
"features": [
{
"type": "DOCUMENT_TEXT_DETECTION"
}
],
"outputConfig": {
"gcsDestination": {
"uri": "ストレージのフォルダパス"
},
"batchSize": 1
}
}
]
}requestBody.json
inputConfig.gcsSource.uriには解析対象のファイルが格納されているCloud Storageのファイルパスを指定します。
例)バケット名:orc_sample_input、ファイル名:sample.pdfの場合
gs://orc_sample_input/sample.pdf
outputConfig.gcsSource.uriには解析結果のjsonファイルを格納するフォルダパスを指定します。
例)バケット名:orc_sample_output、フォルダ名:resultの場合
gs://orc_sample_output/result/
APIの詳細な利用方法についてはリファレンスをご確認ください。
例)バケット名:orc_sample_input、ファイル名:sample.pdfの場合
gs://orc_sample_input/sample.pdf
outputConfig.gcsSource.uriには解析結果のjsonファイルを格納するフォルダパスを指定します。
例)バケット名:orc_sample_output、フォルダ名:resultの場合
gs://orc_sample_output/result/
APIの詳細な利用方法についてはリファレンスをご確認ください。

ApexからPDFファイルの文字列解析をリクエストする
作成したApexを開発者コンソールから実行します。
以下の例では解析対象のファイルパスが"gs://orc_sample_input/JA_EG_CertifiedIntegrationArchitectureDesigner_SU20.pdf"、解析結果の出力先のパスが"gs://orc_sample_output/result/"となっています。
以下の例では解析対象のファイルパスが"gs://orc_sample_input/JA_EG_CertifiedIntegrationArchitectureDesigner_SU20.pdf"、解析結果の出力先のパスが"gs://orc_sample_output/result/"となっています。
GCPLogic.callCloudVisionAPI('gs://orc_sample_input/JA_EG_CertifiedIntegrationArchitectureDesigner_SU20.pdf','gs://orc_sample_output/result/');Apexコールアウト実行
コールアウトが成功すると、指定した出力先に解析結果のJSONファイルが格納されています。
今回はバッチサイズを1に指定したので、PDFファイル1ページごとに1つのJSONファイルが生成されています。
今回はバッチサイズを1に指定したので、PDFファイル1ページごとに1つのJSONファイルが生成されています。

解析結果のJSONファイルの取得
次に、解析結果のJSONファイルを取得し、解析結果を参照します。今回はJSONファイルの中身を取得し、デバッグで検出した文字を出力します。
リクエストのレスポンスのJSON文字列を格納するためのOCRJSONFormatClass.clsと次のコードをGCPLogic.clsに追加します。
リクエストのレスポンスのJSON文字列を格納するためのOCRJSONFormatClass.clsと次のコードをGCPLogic.clsに追加します。
public with sharing class OCRJSONFormatClass {
public InputConfig inputConfig;
public List<Responses> responses;
public class InputConfig {
public GcsSource gcsSource;
public String mimeType;
}
public class Responses {
public FullTextAnnotation fullTextAnnotation;
public Context context;
}
public class FullTextAnnotation {
public List<Pages> pages;
public String text;
}
public class Pages {
public Property property;
public Integer width;
public Integer height;
public List<Blocks> blocks;
}
public class Property {
public List<DetectedLanguages> detectedLanguages;
public DetectedBreak detectedBreak;
}
public class Blocks {
public Property property;
public BoundingBox boundingBox;
public List<Paragraphs> paragraphs;
public String blockType;
public String confidence;
}
public class DetectedLanguages {
public String languageCode;
public Double confidence;
}
public class BoundingBox {
public List<NormalizedVertices> normalizedVertices;
}
public class NormalizedVertices {
public Double x;
public Double y;
}
public class Paragraphs {
public Property property;
public BoundingBox boundingBox;
public List<Words> words;
public String confidence;
}
public class Words {
public Property property;
public BoundingBox boundingBox;
public List<Symbols> symbols;
public String confidence;
}
public class Symbols {
public Property property;
public String text;
public String confidence;
}
public class DetectedBreak {
public String type;
}
public class Context {
public String uri;
public Integer pageNumber;
}
public class GcsSource {
public String uri;
}
}OCRJSONFormatClass.cls
@Future(callout=true)
public static void getOCRResultFileXML(String bucketName,String outputFilePass) {
Http http = new Http();
HttpRequest req = new HttpRequest();
//エンドポイントを指定
String reqPath = 'callout:GCP_XML_API' + '/' + bucketName + '/' + EncodingUtil.urlEncode(outputFilePass, 'UTF-8');
req.setEndpoint(reqPath);
req.setMethod('GET');
req.setHeader('Content-Type', 'text/xml; charset=UTF-8 ');
req.setTimeout(120000);
HttpResponse res = http.send(req);
if (res.getStatusCode() == 200) {
//取得したJSONファイルの文字列をJSONクラスのdeserializeStrictで定義した型に並列化する
OCRJSONFormatClass results = (OCRJSONFormatClass)JSON.deserializeStrict(res.getBody(),OCRJSONFormatClass.class);
//取得結果をループしてデバッグ表示する
for(OCRJSONFormatClass.Responses response : results.responses){
List<String> splitTexts = response.fullTextAnnotation.text.split('\n');
for(String text : splitTexts){
System.debug(text);
}
}
}else {
Map<String, Object> results = (Map<String, Object>) JSON.deserializeUntyped(res.getBody());
System.debug(results);
}
}GCPLogic.cls
今回はContent-Typeをtext/xmlでリクエストしています。text/xmlでリクエストすることでJSONファイルの中身の文字列をレスポンスとして受け取ることができます。Content-Typeをapplication/jsonとすると、JSONファイルのメタデータ情報しか取得することができません。
Apexクラスを作成したら、開発者コンソールで以下のように実行します。
今回は開発者ガイドの1ページ目の解析結果を取得します。
Apexクラスを作成したら、開発者コンソールで以下のように実行します。
今回は開発者ガイドの1ページ目の解析結果を取得します。
GCPLogic.getOCRResultFileXML('orc_sample_output','result/output-1-to-1.json');Apexコールアウト実行
Vision APIの解析結果
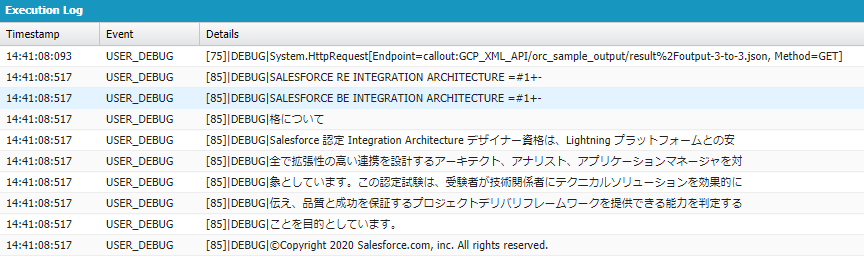
実行した結果をDebug onlyでフィルタした結果が以下になります。

結果①
上から結果を見ていくと、ページ右上あたりにあるSalesforce認定資格のロゴ内の文字「CERTIFIED・」の「ED」が読み取られています。これは、Vision APIがPDFファイル向きを判断し、左→右へ文字が記載されていると認識しているため、ちょうど横向きになっている「ED」のみ認識されたと想定されます。
これは上下反転しているPDFファイルでも文字の向きがそろっていれば解析可能なことを表します。
※ここでは示しませんが実際に解析可能でした。
デバッグの6行目:YOU CAN ~ 14行目:ORCE までも画像内の文字を検出しています。
これは上下反転しているPDFファイルでも文字の向きがそろっていれば解析可能なことを表します。
※ここでは示しませんが実際に解析可能でした。
デバッグの6行目:YOU CAN ~ 14行目:ORCE までも画像内の文字を検出しています。
結果②
出力結果の上から4行目の「ERTIA」ですが、これは「CERTIFIED・」の「ERTIF」を呼んでいると推定されます。JSONファイルの解析結果の1つのパラメーターとして、"confidence"という解析結果の信頼性を示す値があり、0~1で表現され、1に近いほど信頼性が高いことを示します。
「ERTIA」のそれぞれの文字のconfidenceの値は「0.84,0.96,0.76,0.98,0.22」となっており、この結果からも、文字の向きが斜めになっていることから"F"を"A"と読み違えたと推測できます。
「ERTIA」のそれぞれの文字のconfidenceの値は「0.84,0.96,0.76,0.98,0.22」となっており、この結果からも、文字の向きが斜めになっていることから"F"を"A"と読み違えたと推測できます。
結果③
デバッグの15行目:SALESFORCE RÉ ですが、これは"SALESFORCE 認定" の解析結果と思われます。confidenceの値も「0.17,0.05」と低いです。漢字の読み取り精度は低いのでしょうか。
P3の英語、ひらがな、カタカナ、漢字が混同している解析結果を見ると、以下のようになっていました。
P3の英語、ひらがな、カタカナ、漢字が混同している解析結果を見ると、以下のようになっていました。
上記を見ると、英語の大文字が続く文字列内の日本語は解析できてないようですが、先頭文字が英語、以下小文字という文法に従っている本文の英語、ひらがな、カタカナ、漢字の混同は100%正しく解析できています。
英語と日本語が混同する場合は、文法(ルール)が解析するうえで重要そうです。
英語と日本語が混同する場合は、文法(ルール)が解析するうえで重要そうです。
まとめ
いかがでしょうか。今回は詳細まで触れておりませんが、解析結果のJSONファイルには解析して判断した言語の種類、テキストの座標などの情報も保持していますので、帳票のPDFファイルのタイトルの座標にある文字を取得し、見積書なのか、請求書なのかといった判別などにも利用できると思います。
Vision API利用時にご参考になれば幸いです。
Vision API利用時にご参考になれば幸いです。
75 件

